논문 제목
PARE: Part Attention Regressor for 3D Human Body Estimation (ICCV2021)
논문 바로가기
https://arxiv.org/pdf/2104.08527.pdf

위의 그림은 이 논문이 제안한 PARE 모델이 occlusion(가림)에도 mesh를 이미지에 맞게 복원할 수 있다는 것을 보여줍니다. PARE 모델 이전에 나온 기존 모델인 SPIN에 비해 occlusion sensitivity heatmap의 에러 값이 낮음을 확인할 수 있습니다.
논문 제목에서도 알 수 있듯이 Part Attention Regressor를 통해 3D human body를 추정하는 모델을 제안했습니다.
Abstract
Figure 1에서도 알 수 있듯이 기존의 모델이 part occlusion에 약한 모습을 볼 수 있습니다. FIgure 1에 잘 보면 part occlusion이 작은 회색 네모칸으로 주어져있는 것을 볼 수 있습니다. 이렇게 작은 occlusion이 모델의 성능에 큰 영향을 미칩니다. 이러한 문제를 해결하기 위해 soft attention mechanism을 도입했습니다. 이 모델을 PARE (Part Attention REgressor)이라고 하며, body-part-guided attention masks를 예측합니다. 기존의 모델은 global feature representation을 이용하기 때문에 작은 occlusion에도 약한 모습을 보이지만, PARE은 개별 body parts의 visibility에 대한 정보를 이용하여 이웃 body-parts로부터 occluded parts를 예측합니다.
Introduction
In-the-wild 이미지에 있는 사람은 대부분 occlusion되어 있습니다. 기존의 모델은 occluded된 사람의 mesh를 잘 복원하지 못 합니다. 기존의 모델은 input 이미지의 모든 pixels을 pose와 shape parameters를 예측하기 위해 사용됩니다. 그래서 작은 perturbations에도 매우 민감합니다. 이는 Figure 1에서도 확인 할 수 있습니다.
이러한 문제를 해결하기 위해 Part Attention REgressor를 제안했고, 이 모델은 2가지 tasks를 가집니다. 첫 번째, 3D body parameters를 regress합니다. 두 번째, auxiliary task로 body part마다 attention weights를 배웁니다. Attention mask를 part segmentations과 supervise하고 end-to-end train 과정에서는 pose supervision만을 사용했습니다. 이는 네트워크가 자유롭게 풍부한 정보가 있는 곳을 집중할 수 있도록 합니다.
Contribution
- Occlusion sensitivity 분석을 하였습니다. 이를 통해 local part occlusion이 global pose에 어떻게 영향을 미치는 지 확인했습니다.
- 이러한 분석을 통해 body pose와 shape을 regress 하기 위해 pixel-aligned localized feature를 이용하는 새로운 body-part-driven attention 프레임워크를 만들게 되었습니다.
- 이 네트워크는 part visibility 단서를 이용하여 attended regions의 feature를 통합하여 occlusion된 joints를 추론합니다.
- 각 데이터에서 최고의 성능을 내었습니다.
Occlusion Sensitivity Analysis

Figure 2번은 여러 장의 이미지가 있습니다. 각 이미지의 제목은 error를 측정하는 joint를 의미합니다. 예를 들어, 첫 줄 두 번째 이미지는 right ankle의 에러를 heatmap으로 표시한 것입니다. 무릎 부위를 occlusion patch를 적용하면 error가 큰 것을 확인 할 수 있습니다. left ankle의 경우도 허벅지 부분에 occlusion patch를 적용하면 error가 큰 것을 볼 수 있습니다. 반면에 모든 이미지에서 볼 수 있듯이 배경에 occlusion patch를 적용해도 error는 낮은 것을 볼 수 있습니다.
위의 이미지를 통해 다음과 같은 관찰을 할 수 있습니다.
- 에러는 배경보다 몸에서 더 높습니다. 이것은 SPIN 모델이 의미있는 영역에 attend(집중)하는 것을 보여줍니다.
- 기대했던 것처럼, 이미지에 보이는 관절의 경우, 관절이 occlusion되면 높은 에러를 가집니다.
- 이미지에서 자연적으로 가려진 관절의 경우, 해당 관절의 pose를 추정하기 위해 다른 영역에 의존합니다.
- 이러한 의존은 이웃 영역뿐만 아니라 멀리 떨어진 영역에도 영향을 받습니다. (머리 관절을 예측하는데 pelvis(몸통)에 영향을 받음.)
Method

입력 이미지는 CNN backbone을 통해 feature를 추출하고 이 feature는 2D Part Branch와 3D Body Branch로 갑니다.
2D Part Branch
CNN backbone에서 얻은 feature를 convolution layer를 통과하여 attention mask, P 를 얻습니다. GT segmentation과 loss를 걸어 학습을 진행합니다. 이 loss를 통해 visible parts의 attention maps이 해당 영역에 수렴하게 해줍니다. Occluded된 parts에 대해서는 모든 pixel에 대해 0 attention weight를 가지게 합니다. 하지만, 이렇게 되는 것을 원하지도 않고 불가능합니다. 왜냐하면, softmax는 모든 pixel에서의 value의 합이 1이 되어야 하기 때문입니다. 그래서 inital stage에서만 supervision을 이용하고 그 이후로는 supervision을 걸어주지 않습니다.
3D Body Branch
CNN backbone에서 얻은 feature를 convolution layer를 통과하여 body feature, F 를 얻습니다.
Part Attention
P와 F를 reshape하여 P 틸다와 F 틸다를 얻습니다. P 틸다에 softmax를 취하고 transpose하여 F 틸다와 dot product를 합니다.
F 프라임은 6D vector pose와 shape, camera parameter를 추정하는데 이용됩니다.
Loss
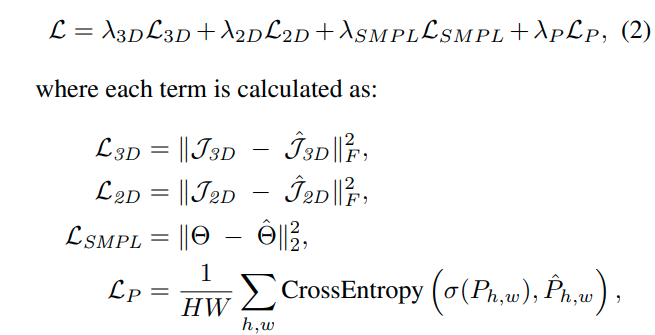
Results


Table 1번과 2번에서 PARE가 SOTA 성능입니다. 한 가지 궁금한 점은, PARE는 table 1번->2번 비교하면, MPJPE가 오히려 늘어나고 SPIN은 약간 줄어드는 게 이상하네요.

더 자세한 내용은 논문 본문을 참고해주세요!
https://arxiv.org/pdf/2104.08527.pdf
'딥러닝 논문' 카테고리의 다른 글
| MANUS 논문 자세한 정리 (1) | 2024.09.06 |
|---|---|
| ControlNet 논문 자세한 정리 (1) | 2024.09.04 |
| 3D human pose estimation in video with temporal convolutions andsemi-supervised training 리뷰 (0) | 2022.04.19 |
| Dynamic Surface Function Networks for Clothed Human Bodies 리뷰 (0) | 2022.03.28 |
| Semantics-Guided Neural Networks for Efficient Skeleton-BasedHuman Action Recognition 리뷰 (0) | 2022.03.22 |



