TalkingGaussian은 ECCV 2024에 나온 논문입니다.
논문 확인: https://arxiv.org/abs/2404.15264
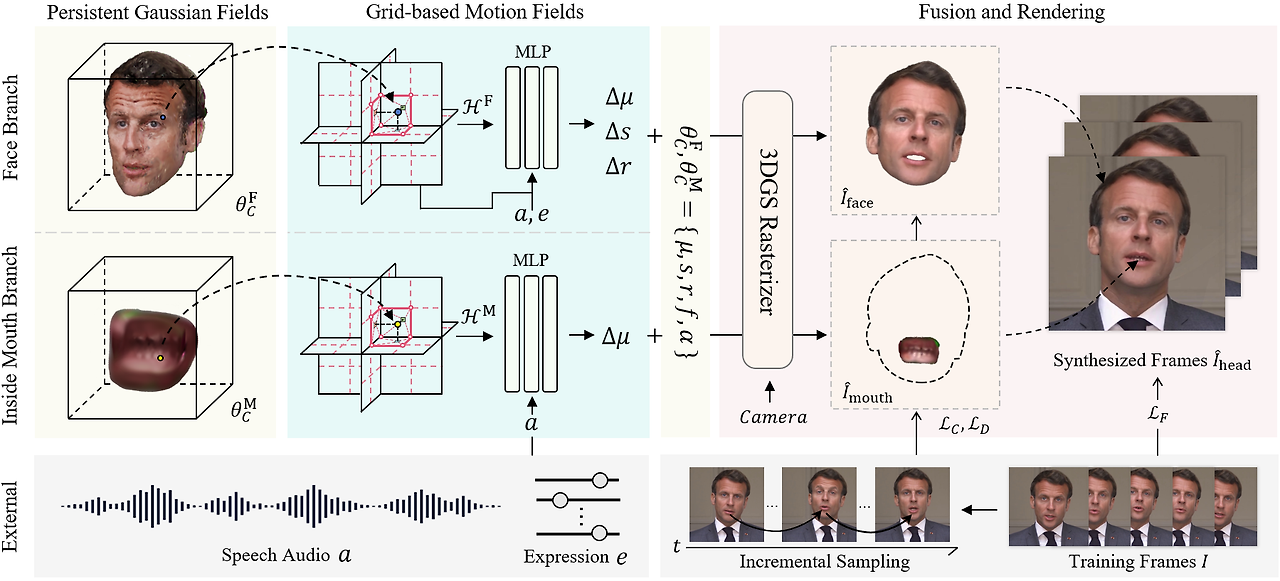
TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
Radiance fields have demonstrated impressive performance in synthesizing lifelike 3D talking heads. However, due to the difficulty in fitting steep appearance changes, the prevailing paradigm that presents facial motions by directly modifying point appeara
arxiv.org
TalkingGaussian은 오디오 입력으로 말하는 얼굴 아바타를 생성하는 논문이며, representation으로 3D Gaussians을 이용합니다.
기존 코드는 우분투 18.04, CUDA 11.3을 이용했지만, 저는 우분투 22.04, CUDA 11.7을 이용했습니다.
우분투 22.04는 CUDA 11.3을 설치를 못하더라고요. (혹시 되시는 분은 알려주세요!) 그리고 추가적으로 어떤 모델의 ckeckpoints를 다운로드하여야 했는데 기억이 안 나네요. 혹시 하시다가 에러 나시는 분 있으시면 알려주세요.
Environment Setting
TalkingGaussian github 주소는 다음과 같습니다.
https://github.com/Fictionarry/TalkingGaussian?tab=readme-ov-file
GitHub - Fictionarry/TalkingGaussian: [ECCV'24] TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Spl
[ECCV'24] TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting - Fictionarry/TalkingGaussian
github.com
아래의 명령어를 통해 git clone을 하셔야 합니다.
git clone https://github.com/Fictionarry/TalkingGaussian.git --recursive
recursive를 하는 이유는 submodules 폴더에 있는 "diff-gaussian-rasterization @ d986da0"와 "simple-knn @ f155ec0"도 함께 clone 하기 위함입니다.
환경 설정 하실 때, 저는 CUDA 11.7 버전, torch는 1.13.1 버전을 이용했기 때문에 아래와 같이 environment.yaml을 수정했습니다. 보시면 아시겠지만, cuda, torch, gridencoder, submodules과 관련된 명령어는 주석으로 처리했습니다. 그리고 pyaudio도요. 안 그러면 환경 설정 도중 에러가 났습니다.
name: talking_gaussian
channels:
- pytorch
- conda-forge
- defaults
dependencies:
# - cudatoolkit=11.7
- plyfile=0.8.1
- python=3.7.13
- pip=22.3.1
# - pytorch=1.13.1=py3.7_cuda11.7_cudnn8.5.0_0
# - torchaudio=0.13.1=py37_cu117
# - torchvision=0.14.1=py37_cu117
- tqdm
- ffmpeg
- openh264
- pip:
# - ./submodules/diff-gaussian-rasterization
# - ./submodules/simple-knn
# - ./gridencoder
- numpy
- pillow
- scipy
- tensorboard
- opencv-python
- tensorboardX
- pandas
- tqdm
- matplotlib
- PyMCubes==0.1.4
- rich
- packaging
- scikit-learn
- face_alignment
- python_speech_features
- numba
- resampy
# - pyaudio
- soundfile
- configargparse
- lpips
- imageio-ffmpeg
이후 아래 명령어로 환경 설정해 주세요!
conda env create --file environment.yml
conda activate talking_gaussian
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
pip install ./submodules/diff-gaussian-rasterization
pip install ./submodules/simple-knn
pip install ./gridencoderpip install tensorflow-gpu==2.8.0도 설치하라고 하는데, 저는 설치하니깐 학습할 때 에러가 나서 설치하지 않았어요. 설치했다가 삭제했답니다. 삭제했다가 다시 설치하니깐 괜찮네요. 오디오 전처리할때 tensorflow가 필요해서 설치해야 하긴 합니다.
Data Preparation
3DMM model을 준비해야 합니다. 아래의 명령어로 준비하면 됩니다.
bash scripts/prepare.sh
중요
이때, data_utils/face_tracking/3DMM/01_MorphableModel.mat는 따로 설치되지 않습니다. 이후 이게 에러가 발생할 테니 미리 다운로드하여 줍시다. 아래 링크 참고해 주세요.
01_MorphableModel.mat 다운로드 받기
아래의 링크로 가서 정보 입력하면 입력한 이메일을 통해 다운로드 받을 수 있습니다. 2019년 최신 버전 말고 아래 링크를 이용하셔야 합니다.https://faces.dmi.unibas.ch/bfm/main.php?nav=1-2&id=downloads Morpha
grow-up-by-coding.tistory.com
BFM을 변환하는 명령어입니다. 실행해 주세요!
cd data_utils/face_tracking
python convert_BFM.py
cd ../..
easyportrait 관련 명령어입니다. 실행해 주세요!
# prepare mmcv
conda activate talking_gaussian
pip install -U openmim
mim install mmcv-full==1.7.1
# download model weight
cd data_utils/easyportrait
wget "https://n-ws-620xz-pd11.s3pd11.sbercloud.ru/b-ws-620xz-pd11-jux/easyportrait/experiments/models/fpn-fp-512.pth"
cd ../..
비디오 데이터는 다음 링크에서 준비할 수 있습니다. https://drive.google.com/drive/folders/1E_8W805lioIznqbkvTQHWWi5IFXUG7Er?usp=drive_link
talking_gaussian_dataset - Google Drive
이 폴더에 파일이 없습니다.이 폴더에 파일을 추가하려면 로그인하세요.
drive.google.com
macron (약 6분), may (약 4분) 2가지 비디오가 있는데 may가 더 짧습니다. may.mp4를 data/may/may.mp4에 저장해 주세요.
Preprocessing
아래 명령어를 통해 전처리를 진행해 주세요. 꽤 오래 걸립니다. 오디오와 특징 추출, 이미지로 분리 등 다양한 전처리가 진행됩니다.
python data_utils/process.py data/may/may.mp4
Action Units를 얻어야 하는데요. 이건 아래의 링크를 참고해 주세요.
OpenFace 설치 및 실행
TalkingGaussian 실행을 시도하려고 하다가 OpenFace를 설치해야 했습니다. 생각보다 복잡한 과정이어서 글로 정리해두려고 합니다.Install (Ubuntu 22.04)OpenFace 설치 전 미리 있어야 할 dependency를 설치해주
grow-up-by-coding.tistory.com
FeatureExtract -f "data/may/may.mp4" -out_dir "data/may"FeatureExtraction을 하고 나면 data/may/may.csv가 생길 텐데, may.csv를 au.csv로 이름을 바꿔주세요.
다음은 tooth mask를 생성해야 합니다. 아래 명령어를 실행해 주세요.
export PYTHONPATH=./data_utils/easyportrait
python ./data_utils/easyportrait/create_teeth_mask.py ./data/mayTrain
학습하기 전에 조심해야 할 것이 있습니다.
- data/may/aud.npy를 data/may/aud_ds.npy로 변경해 주세요.
- scene/dataset_readers.py에서 118, 119, 126번째 줄에 AU 앞에 띄어쓰기 모두 없애주세요.
- 118번째 줄: au_blink = au_info['AU45_r'].values
- 126번째 줄: _key = 'AU' + str(i).zfill(2) + '_r'
- 119번째 줄: au25 = au_info['AU25_r'].values
명령어
bash scripts/train_xx.sh data/may output/may 0
학습이 돌아가고 output/may에서 결과를 확인해 주세요.
위 결과는 학습 결과입니다. 오디오가 원래는 없어서 어색하네요.
Inference
오디오 준비하기.
gTTS를 이용하여 text에서 speech 오디오를 생성할 수 있어요.
https://colab.research.google.com/drive/1G2jPJezq8OwmJEp8dbtf-8LS2Lj24wnT?usp=sharing
text2audio.ipynb
Colab notebook
colab.research.google.com
위 colab에서 생성한 output_proc.wav를 이용해 주세요. 이 오디오를 전처리하는 코드 명령어는 아래와 같습니다.
python data_utils/deepspeech_features/extract_ds_features.py --input data/output_proc.wav # saved to data/<name>.npy
이후, 전처리된 오디오.npy 파일을 이용하여 talking avatar를 생성할 수 있습니다.
python synthesize_fuse.py -S data/may -M output/may --use_train --audio data/output_proc.npy
역시 오디오가 없는 비디오만 생성이 됩니다. 특이하게 저장 폴더가 train입니다.
저장폴더: output/first/train/ours_None/renders/out.mp4
추가적인 코드를 통해 비디오와 오디오를 합칠 수 있습니다.
merge_video_w_audio.py입니다.
python merge_video_w_audio.py --input-video output/first/train/ours_None/renders/out.mp4 --input-audio data/output_proc.wavimport os, os.path as osp
import subprocess
import argparse
def main(args):
if args.output_video is None:
dirname = osp.dirname(args.input_video)
basename = osp.basename(args.input_video)
args.output_video = osp.join(dirname, basename.split('.')[0]+"_w_audio.mp4")
subprocess.run([
'ffmpeg', '-i', args.input_video, '-i', args.input_audio,
'-c:v', 'copy', '-c:a', 'aac', args.output_video
])
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--input-video', type=str, help='Path to input video')
parser.add_argument('--input-audio', type=str, help='Path to input audio')
parser.add_argument('--output-video', type=str, help='Path to output video')
args = parser.parse_args()
main(args)
Hello, world! Nice to meet you.라는 오디오로 합성한 결과입니다.
'딥러닝 코드' 카테고리의 다른 글
| Stable-dreamfusion 환경 설정 (5) | 2024.10.04 |
|---|---|
| ICP 알고리즘, 회전, 이동, 2개의 3차원 점 집합 포즈 정렬하기 (0) | 2024.09.18 |
| SuGaR 코드 돌려보기 (1) | 2024.09.14 |
| OpenFace 설치 및 실행, 사용법 (0) | 2024.09.07 |
| ControlNet 학습하기, huggingface 코드 (0) | 2024.08.30 |



